这个脚本作用于百度网盘的Web页面,你输入读秀、CADAL等图书的编号后,它自动定位到相应图书所在的文件夹,前提是文件是按图书ID组织的,比如把读秀SS号为12345678和12345679的书都存放在/1/2/3/4/5/6/7。
如果你的网盘中没有以这种方式组织的资源,安装此脚本没有意义。下面是个gif动画,看一下就明白了。😀
脚本的用法
获取图书ID后,粘贴到脚本添加的输入框中,回车即可。脚本会定位到相应文件夹并高亮显示你要找的文件。如果文件不存在,输入框旁边的文字会显示tip。
具体请看下面的gif动画,如有问题请评论区留言,或者根据gif上的地址给我发邮件。
图书ID是安装文献互助小帮手后获取的,查图书ID的网址原作者写的很详细,这里就不赘述了。
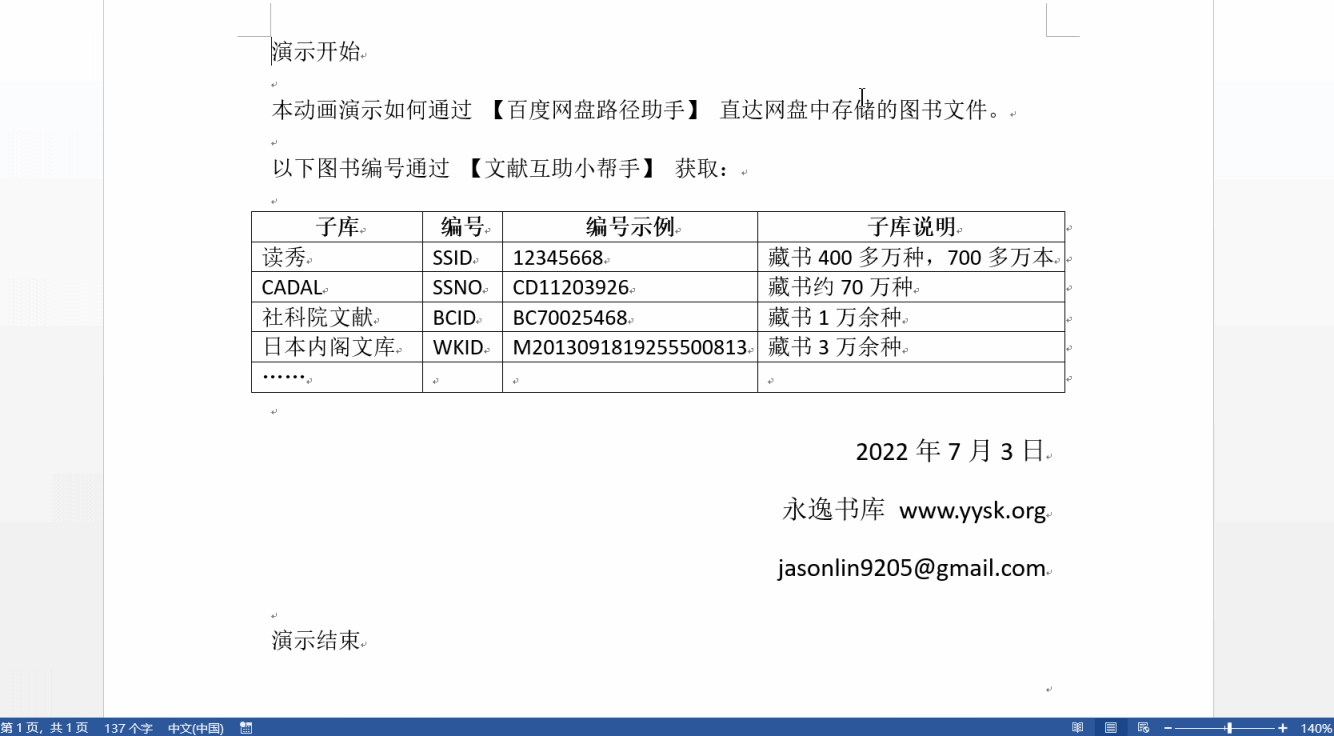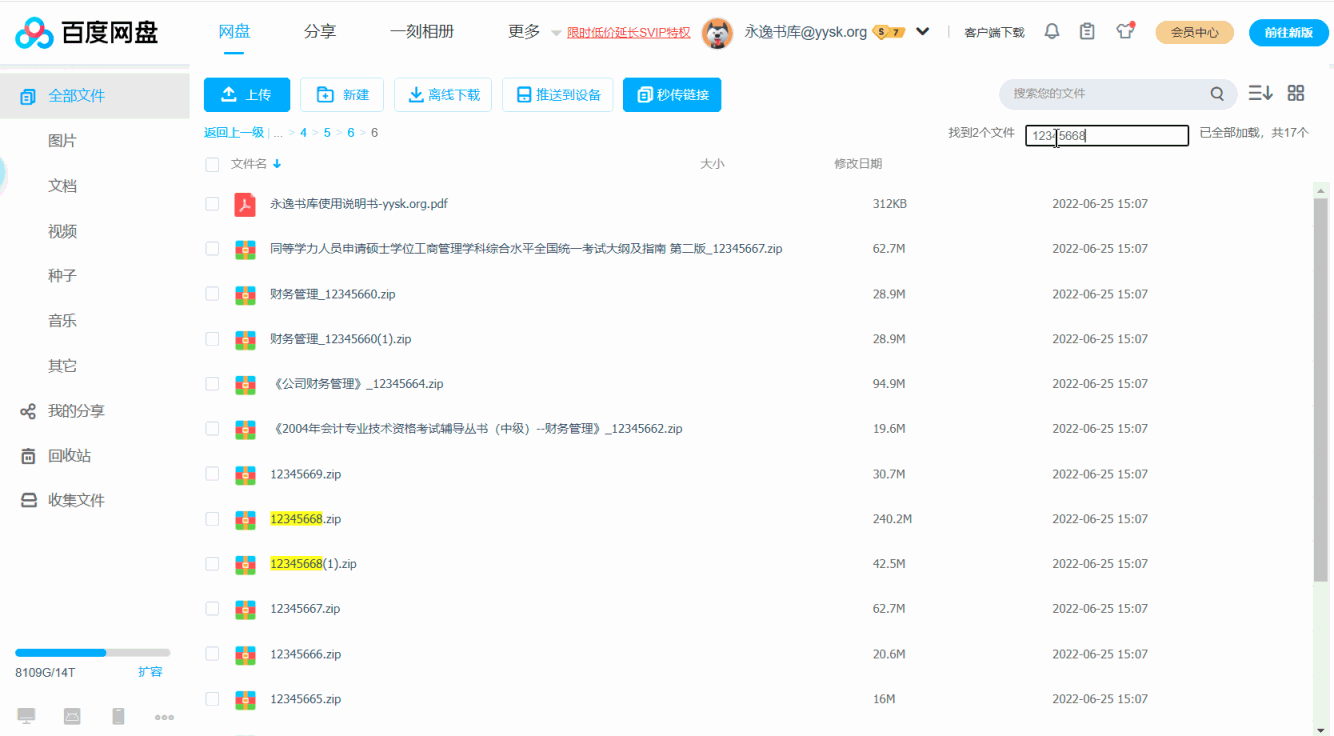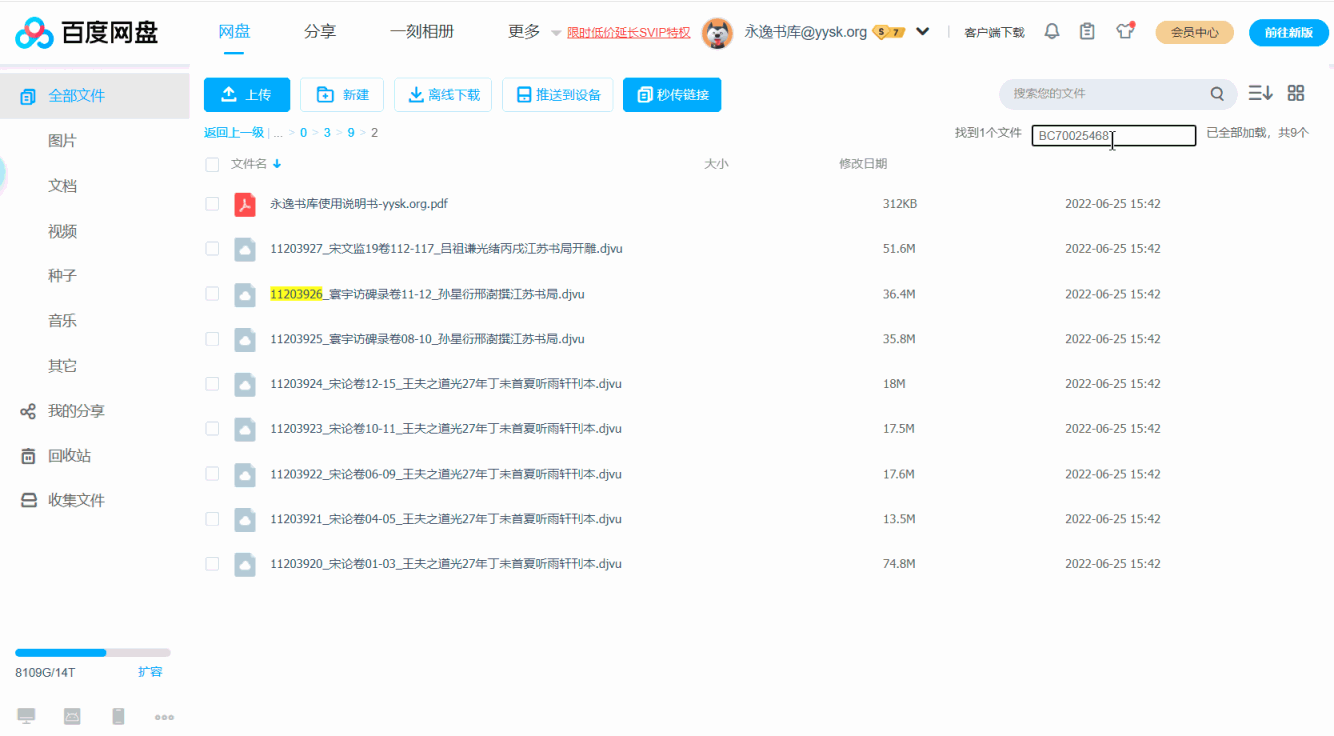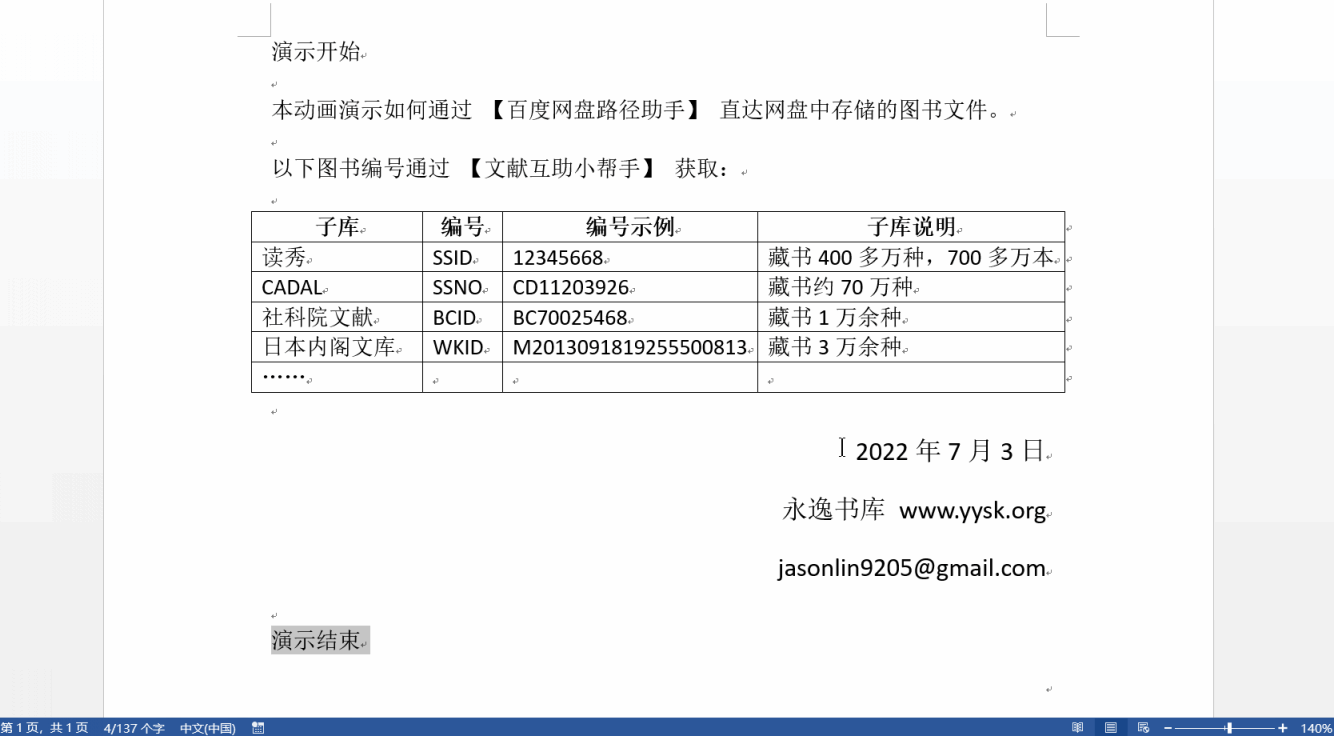
脚本支持百度网盘的新版UI和旧版UI,演示动画中是旧版UI。复制粘贴动作和窗口切换没有用鼠标,而是用了键盘快捷键,所以动画上也看不到。
关于永逸书库和脚本之缘起的啰嗦
学校图书馆里中文书很少,通过其他途径买实体书也很不便宜,于是经常从网上下书,但很多书网上是搜不到的,能找到的也比较费时。
后来发现了读秀自建库这个神器,便果断重金买了号称八百万资源的读秀书库,但拿到手后发现它可用性太差了,因为一个目录里面数万个文件,且存放没有规律,需要某本书时根本无从找起。花钱打了水漂,我郁闷苦恼了一阵子。
某天灵光一现,我想出了解决办法,可以按读秀SS号重新组织文件的存放目录啊。比如把读秀SS号为12345678和12345679的书都存放在/1/2/3/4/5/6/7,点几次就能定位到一本书,并且即使算上一书多版,文件夹内文件数量基本也不会超过30。当然,工作量是无比艰巨的,且不说获取全部文件的列表、从文件名中识别出SS号等困难,光是给所谓dx2、dx3、dx4.0、dx3遗漏、dx3补这几个叠床架屋的文件夹去重,就异常麻烦。后来工作也证明,我买的资源虽然很全,但重复率相当高,重复文件占比约一半。
犹豫了几天后,还是决心开干。深处大乡村,娱乐生活十分贫乏,权当解闷了。悲剧的是,事后证明这个坑比原先预估的深太多,不止一次把我搞郁闷了。
简言之,我投入了近乎全部的业余时间,就做这个整理工作,期间不仅锻炼了手指,还复习了perl/python/shell等各类脚本的写法……数百T的资源显然不可能下载到本地、整理后再上传,只能线上整理。但最初存资源的网盘被限制写入了,要分批转存到其它账号慢慢整理,当时遇到的最大困难是空间不足,新注册(不可用)的账号只有100G,开了SVIP会员也不过5T,于是第二次投入重金买了二十多个小号并开通会员,后来买不动了,便聪明、勤奋地用起了回收站SL大法,历经小半年、困难无数,终于整理完了读秀资源。
然后发现了Throne大神的文献互助小帮手,才知道读秀之外竟然还有CADAL等一众其它资源,顿觉缺憾。后来了解到这几个书库总的体量还不及读秀零头,便索性各处搜罗到手,花了两个多月,按同样方式将它们整理好。
最后要将全部资源汇总到一个账号里面去,于是找到最初卖我书库的人付费扩容,但被告知之前的扩容方法已失效,他现在不做了。我顿时石化,不知如何是好。多方查询后发现还是有办法的,于是第三次重金学艺,购得几个文档和视频,钻研了几天学会了扩容。
总之,花了很多钱,用了巨多时间,消耗了N多脑细胞和肝细胞,把几个我知道的图书资源库弄到了一块儿,搞成了这个自建库-永逸书库。
本来想着查到图书编号,点几次就能找到书,应该很方便,但用了几天发现还是略慢,特别百度网盘的新版UI不知为何很慢,有时点到一本读秀书的存放文件夹要半分多钟,不能忍,琢磨了半天,然后就有了这个脚本。没有写油猴脚本的经验,便参考着文献互助小帮手一点点改,并获Throne同意借用了不少代码,特此致谢!
其它
此脚本是免费的,且没有任何主动的网络交互,只是通过更改url促使网盘页面更新文件列表,因此无账号泄露、隐私之虞,欢迎使用。你可以按我的思路自建书库,或者联系我有偿帮建书库,从此一劳永逸!如果你发现了其它好的资源,也欢迎向我推荐,谢谢!
